You know, the most amazing thing happened to me tonight. I was coming here, on the way to the lecture, and I came in through the parking lot. And you won’t believe what happened. I saw a car with the license plate ARW 357. Can you imagine? Of all the millions of license plates in the state, what was the chance that I would see that particular one tonight? Amazing!
-Richard Feynman (source)
A friend on Facebook commissioned a survey with three conditions, which were to be assigned randomly to participants (uniform distribution). The number of responses was
condition A: 58
condition B: 94
condition C: 108
total: 260
Seeing the lopsided result, she called the survey company to ask what was up. The representative said it was just random chance. How should one react? What sort of reasoning is useful here, and what is not? Is something strange going on with the survey?
If you crunch through some quick math, you’ll see that if the survey is fair, the odds of getting a result as extreme as 58/260 via random chance are a bit less than one in a thousand. (I’m accounting for over- or under-representation in any of the three categories.) How meaningful is that?
Suppose you are walking home and find a 20-dollar bill. The odds of that might be about 1/1000, but you likely don’t think anything fishy is going on. You chock it up to good luck and pocket the bill. But next suppose you remember a time when you found a 20-dollar bill when you were walking home as a little kid, and you realize you found it right outside your grandparents’ house (which you pass on the way), and they happened to be watching from the window when it happened. These circumstances don’t change the probability of finding a 20-dollar bill by random chance, but they change our estimate of the probability that finding the bill was a fluke. How meaningful an unlikely result is depends on not only how unlikely it is, but also on the plausibility of competing alternatives.
This is captured in Bayes formula. For the survey, it is
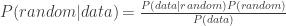
where 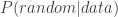 is the probability the survey process was a fair, uniform, random one given the observed 58-94-108 split.
is the probability the survey process was a fair, uniform, random one given the observed 58-94-108 split. 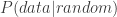 is the probability of observing our results given a fair random process.
is the probability of observing our results given a fair random process. 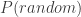 is the prior probability we assign to the process being a fair random one, and
is the prior probability we assign to the process being a fair random one, and 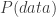 is the overall chance of seeing our 58-94-108 split under any circumstances, including unfair ones.
is the overall chance of seeing our 58-94-108 split under any circumstances, including unfair ones.
The easy one is . It comes to 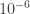 (see calculation here).
(see calculation here).
Discussion of the issue, then, ought to focus on estimates for and . In part, it did
Are you counting people as they start the survey or as they finish? Because if it’s the latter, and option A is more work than the other two…
(suggests isn’t very high due to varying attrition rates, and that isn’t very low because varying-attrition could cause the observed bias.)
mostly I assume that it is random because randomness is pretty easy to code
( is high)
Actually, what you should be calculating is the Bayes factor, given the observed data, of a uniform distribution vs. a categorical distribution with a Dirichlet prior.
(Focuses on . However, it suggests a slightly-different metric to look at than estimating the probability that the survey process is fair. Seems like a good suggestion, but it’s not my main point here.)
How does one calculate the probability that Qualtrics would make a mistake?
(focusing on )
I believe that if something went wrong with that kind of coding, the outcome would look very different (like it would skip one group altogether)
( is low)
One thing everyone should keep in mind is that the alternative hypothesis here is NOT “their random number generator is broken.” (I mean, that’s possible, but it’s not on my list of top ten likeliest alternative hypotheses).
The alternative hypotheses here are things like “I misunderstood how to use Qualtrics ‘randomizer’ function.” Or, “Qualtrics intentionally assigns lower probabilities to longer test conditions.” Or “There’s a higher dropout rate in this test condition.” (Although I *think* that last hypothesis has been falsified by now.)
(Suggests why isn’t necessarily so high, and why is significant.)
Ultimately, the estimate you generate will be subjective, i.e. based on your priors and your assumptions about how to model the survey process. That’s why we see people using a lot of heuristic reasoning about the calculation – heuristics are how we deal with subjective estimates.
But in addition to discussion aimed at estimating the components that go into the Bayesian calculation, there was an entirely different type of heuristic reasoning, one focusing on human biases
I think Kahneman and Tversky did research on this? On coin flips people think HTHTTHT is more likely than HHHHHHH because it “looks more random.” Both are equally likely.
The funny thing about this (related to what A—- was saying) is that we’ve got research which shows just how difficult it is for human beings to accept randomness when they see it.
although a chi-square test shows that it’s a highly unlikely result, anything is possible, and it would be unusually NOT to see some unlikely results.
The statistical calculation only gives us the probability that such an outcome would occur. It doesn’t rid us of our preconceived notion that it should not occur, nor does it remind us that even low probability events occur quite often.
What I’m saying is that a program that has been used hundreds (or perhaps thousands?) of times to randomize subjects into conditions will often produce an outcome in the tails of the distribution.
The idea seems to be that one shouldn’t be alarmed just because your model says an event of low probability occurred. Even if your models of the world are in general correct, so many things happen that you’ll observe rare events once in a while. Further, we’re biased to make a big deal out of things, thinking they’re not random when they are. This bias in what we notice is the basis for Feynman’s joke – no one ever points out every mundane thing that occurs; only the few that seem surprising to them. Most, they don’t notice.
But “human biases” doesn’t seem to have any obvious spot in Bayes’ formula. The calculation gives a probability that doesn’t have anything to do with your biases except insofar as they affect your priors. Who cares whether the program has been used hundreds or thousands of times before? We’re only interested in this instance of it, and we don’t have any data on those hundreds or thousands of times. The only extent to which that matters is that if the program has been used many times before, it’s more likely that they’ve caught any bugs or common user errors.
In the end, the “unlikely events are likely to occur” argument doesn’t seem relevant here. If we looked at a large pool of surveys, found one with lopsided results, and said, “Aha! Look how lopsided these are! Must be something wrong with the survey process!” that would be an error, because by picking one special survey out of thousands based on what its data says, we’ve changed . That is, it is likely that the most-extreme result of a fair survey process looks unfair. But we didn’t do that here, so why all the admonitions?
Another point made by commenters was that HTHTTHT is equally-likely with HHHHHHH given a fair coin, but only the second one raises an eyebrow. This is because HTHTTHT is one of a set of a great many similar sequences while HHHHHHH is unique. But this doesn’t seem relevant here, either. We didn’t look at the exact sequence of responses 260 (BBCABACCABAC…) and claim it was unlikely. All sequences are equally unlikely given a fair random process. But instead we looked at a computed statistic – the distribution of A, B, and C, which captures most of what we’re interested in. So again, why did commenters bring this up?
Maybe I’m missing an important point, but my guess is that it’s just pattern matching. “Oh, someone is talking about an unlikely thing that happened. Better warn them about Feynman’s license plate.” Of course, we do pattern-matching all the time because it usually works. But we also need to get feedback whenever our pattern-matching fails, then try to figure out why it failed, then try to update the pattern-matching software to work better next time, gradually giving fewer false positives and more true positives. There’s a tradeoff between them, and I’d guess it’s better to err on the side of committing false positives, since you can go build a general skill of going back and checking over what you’ve said carefully after initially pattern-matching it, especially in writing.
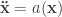
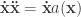

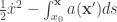

") . That is, it is likely that the most-extreme result of a fair survey process looks unfair. But we didn’t do that here, so why all the admonitions?
. That is, it is likely that the most-extreme result of a fair survey process looks unfair. But we didn’t do that here, so why all the admonitions?